We've all been there. Staring at page 47 of a 90-page research paper, eyes glazed over, trying to find that one statistic the author mentioned somewhere in the introduction. Or maybe it was the methodology section? The caffeine wears off, and the will to live slowly fades. The pain is real, especially for students, academics, and anyone whose job involves wading through dense, jargon-filled documents.
For years, the process has been the same: CTRL+F, frantic keyword guessing, and endless scrolling. But what if you could just… ask the paper a question? Like you would ask a colleague? “Hey, what was the main conclusion here?” or “Remind me, what was the sample size for experiment two?”
This is the dream, right? And it’s a dream that tools like ResearchGPT promised to make a reality. I stumbled upon this project on GitHub a while back and my inner SEO/data nerd got pretty excited. An AI research assistant? Sign me up.
So, What Was ResearchGPT Supposed to Be?
In a nutshell, ResearchGPT was designed as a pretty straightforward but powerful application. It gave you a simple interface to upload a PDF file—or even just plug in a link to one online. From there, it would work its magic, letting you have a full-blown conversation with the document.
But here's the part that really caught my eye, the feature that separates the genuinely useful tools from the tech demos: it provided source information. When you asked a question and it gave you an answer, it would also tell you the exact page number and show you the original text it used to come up with that answer. For anyone in research, that’s not just a feature; it's the holy grail. It’s the difference between a black box spitting out answers and a trustworthy assistant that shows its work.
It was all there, a self-hosted solution for anyone with a bit of technical know-how and an OpenAI API key. I was ready to spin it up and give it a go. And then I saw it.
The Dreaded 'Archived' Banner: A Plot Twist
If you spend any time on GitHub, you know the feeling. You find a cool project, your mind races with possibilities, and then you see that little yellow banner: “This repository is archived.” It’s the digital equivalent of finding a ghost town. The lights are off, and nobody's home.
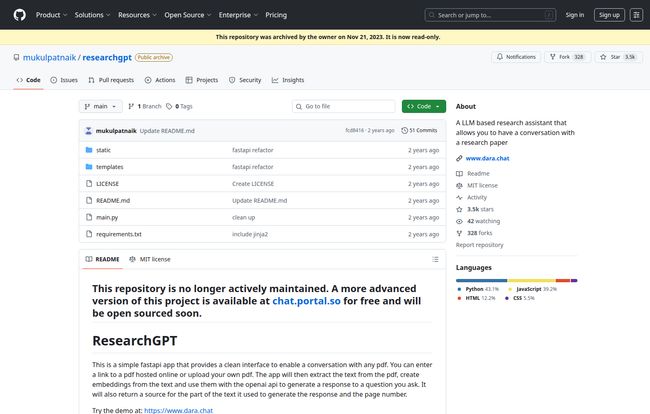
The original ResearchGPT repository, created by Mukul Patnaik, was officially archived in November 2023. This means the code is still there to look at, but it's no longer being updated or maintained. For a project that relies on external APIs like OpenAI's, that's basically a death sentence.
My heart sank a little. But then I read the fine print. A note right at the top of the page pointed to something new, something better.
“A more advanced version of this project is available at chat.portal.so for free and will be open sourced soon.”
Ah, so it didn't die. It evolved. The project has moved on to a new home, which now seems to be called simply Portal. This is where the story gets interesting again.
Visit ResearchGPT
How These AI PDF Readers Actually Work Their Magic
Before we go further, you might be wondering what's happening under the hood. It’s not actual magic, though it feels like it. The process, which was at the core of ResearchGPT and is used by its successors, is a clever bit of engineering. I think of it as a three-step dance.
-
The Reading & Chunking: First, the system ingests the entire PDF and extracts all the text. It then breaks this wall of text down into smaller, manageable chunks. Think of it like tearing a book into individual, meaningful paragraphs.
-
Creating a 'Concept Map': This is the really clever part. It takes each of those text chunks and uses a model to create what are called 'embeddings'. This is a fancy term for turning text into a string of numbers (a vector) that represents its meaning. The result is a highly detailed, searchable numerical map of every concept in the document.
-
The Conversation: When you ask a question, the system turns your question into an embedding too. It then compares your question's embedding to the map of the document to find the most relevant text chunks. It hands these chunks—along with your original question—to a Large Language Model (like GPT-4) and says, “Here’s the user’s question and here’s the most relevant context from the document. Please formulate a helpful answer and tell me which chunk you used.”
That last step is the secret sauce. It’s why you get a nice conversational answer and that all-important page number. It’s a beautiful system.
The Pros and Cons From My Perspective
Having played with tools like this, I've got some pretty strong feelings about where they shine and where you need to be careful.
What I Absolutely Love
The biggest pro, by a country mile, is the time saved. The ability to quickly query a document for its core findings, methodology, or specific data points without a manual search is a massive productivity booster. The fact that the newer versions like Portal are hosted platforms means you don’t have to mess around with setting up servers or managing API keys. It just works. And I have to say it again: the source referencing is a non-negotiable feature for me. It builds trust and turns a cool toy into a serious tool.
Some Things to Keep in Mind
Now, for the dose of reality. First, the output is only as good as the AI model it's built on. These models can still make mistakes or “hallucinate” information, even when given source text. Always, and I mean always, click the source link to double-check the original context. Second, and this is a big one for me, is privacy. When you upload your document to a free online service, you should always ask yourself where that data is going and how it's being used. For non-sensitive, public research papers, its fine. For proprietary corporate reports or unpublished research? I'd be a little more cautious.
What's the Deal with Pricing?
This is always the million-dollar question, isn't it? The original ResearchGPT was 'free' in the sense that the code was open-source, but you had to pay for your own OpenAI API calls. Depending on how much you used it, that could get pricey.
The new platform, Portal, is advertised as free. Now, my years in this industry have made me a bit of a cynic. 'Free' can often mean 'free for now' or 'free with certain limits.' As of writing this, it seems genuinely free to use, which is fantastic. They may introduce premium tiers in the future for more advanced features, which is a pretty standard business model. I actually prefer that to a model where my data is the product.
Just to be clear, if you see pricing plans on GitHub itself (like the Free, Team, and Enterprise tiers), that's for hosting your code on their platform. It has nothing to do with the cost of using a specific tool like Portal.
Frequently Asked Questions
Is ResearchGPT still active?
No, the original GitHub project is archived and no longer maintained. Its creator has moved on to a newer, more advanced project.
What is the new version of ResearchGPT?
The spirit of ResearchGPT lives on in a platform called Portal. You can find it at portal.so. It offers a similar 'chat with your documents' experience in a more user-friendly, hosted environment.
Do I need an OpenAI API key for Portal?
No. Unlike the original self-hosted ResearchGPT, the Portal platform handles all the backend API connections for you. You can just sign up and start uploading documents.
Is Portal really free to use?
Yes, at the moment, the service is offered for free. It's always a good idea to check their website for the most current pricing information, as they may introduce paid plans in the future.
How accurate are the AI's answers?
Accuracy is generally high but depends on the quality of the PDF and the complexity of the question. The best feature is that it provides source citations, so you can and should always verify the AI's answers by checking the original text yourself.
Final Thoughts
So, where does that leave us? The original ResearchGPT may be a relic of the past, but it was a fantastic proof-of-concept that paved the way for more polished, accessible tools like Portal. The ability to have an intelligent conversation with your documents is, without a doubt, a game-changer for anyone who deals with information overload.
It’s not about making us lazy or replacing critical thinking. I see it as the opposite. By outsourcing the tedious task of searching and locating information, we free up more of our mental energy for what truly matters: understanding, analyzing, and generating new ideas. And that’s something I can definitely get excited about.
References and Sources
- Original ResearchGPT GitHub Repository (Archived)
- Portal - The Successor to ResearchGPT
- OpenAI API Page
- Redis Installation Guide (for the original project)