I swear, if I see one more headline about a trillion-parameter model that can write a sonnet while juggling chainsaws, I might just lose it. We’re all so obsessed with the size of our AI, but we keep forgetting the golden rule, the one that’s been true since the first punch-card computer: garbage in, garbage out.
We’ve all been there. You spend weeks, maybe months, preparing a dataset. You feed it to your shiny new LLM, hold your breath, and the output is… well, let's just say it's 'creatively challenged'. It’s biased, it hallucinates facts, it leaks personal information. It's a mess. Why? Because your data was a mess.
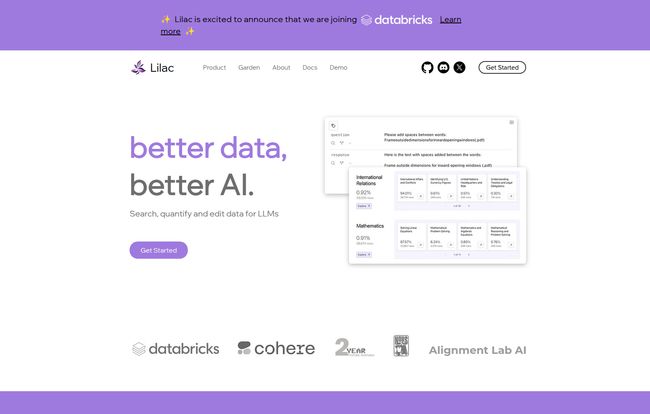
It’s a frustrating cycle. But what if there was a tool designed specifically to break it? A tool that acts like a combination of a powerful magnifying glass and a surgeon's scalpel for your messy, sprawling datasets? That’s the promise of Lilac. And frankly, after kicking the tires on it, I'm pretty impressed. It’s no wonder they just got snapped up by Databricks – a move that screams “this is the real deal.”
So, What Exactly Is This Lilac Thing?
In the simplest terms, Lilac is an open-source tool built to help you see, understand, and fix your data before it ever gets near your model. It’s made for AI practitioners and data scientists—the people in the trenches. It’s not about building the model itself; it’s about making sure the bricks you're using to build it are solid gold.
Think about it. You have a massive text dataset. Millions of lines. How do you find all the near-duplicates? Or the documents that contain sensitive PII? Or just the stuff that’s completely irrelevant to your topic? You could write a mountain of Python scripts, or you could use a tool that has all of that built right in. That's Lilac. It lets you search, quantify, and edit data for your LLMs with a slick user interface layered on top of a powerful Python library.
And the best part? It’s open-source. Free. No scary enterprise licenses or per-seat pricing models. Just pure, community-driven power.
Why Your LLM Project Desperately Needs a Data Curator
Let’s be honest for a second. Data cleaning is the least glamorous part of AI. It’s the digital equivalent of washing the dishes after a huge party. Nobody wants to do it, but if you don't, your whole house starts to stink. Building an LLM on top of a dirty dataset is like building a skyscraper on a foundation of mud and soggy bread. It’s just not going to stand up.
Your model’s performance, its biases, its reliability—it all comes back to the data. Jonathan Frankle, the Chief Scientist over at MosaicML (and now Databricks), said it best: Lilac gives you a “simple path to understanding the concepts in datasets.” It’s not just about deleting bad rows; its about fundamentally understanding what you're working with.
My Favorite Lilac Features (The Good Stuff)
Alright, let’s get into the meat of it. I’ve played around with it, and a few things really stand out. This isn’t just another data viewer.
Blazing Fast Computations in the 'Lilac Garden'
Okay, the name “Lilac Garden” is a bit whimsical, but the performance is anything but. The homepage boasts it can cluster and title 1 million data points in 20 minutes and embed data at a rate of half a billion tokens per minute. Those aren't just marketing numbers; that's legitimately fast. For anyone who's ever left a Jupyter notebook running overnight just to process a dataset, that speed is a game-changer. It turns a day of waiting into a coffee break.
Search That Actually Understands You
Keyword search is so 2010. Lilac comes packed with semantic search. This means you can search for a concept, not just a word. For example, you could search for “unhappy customer feedback” and it will find reviews that say “I was really disappointed” or “this product is terrible,” even if the word “unhappy” never appears. You can start with a fuzzy idea and use Lilac to refine it, hunting down the exact data points you need. It's incredibly powerful for topic modeling and data exploration.
Visit Lilac
The Automatic Data Janitor
This is a huge one. Lilac can automatically scan your dataset for a whole host of problems. It can flag Personally Identifiable Information (PII) like names and email addresses, which is a massive win for privacy and compliance. It can sniff out near-duplicates that can skew your model’s training, and it can even detect the language of each document. You can even create your own custom “signals” to flag whatever is important for your specific project. This automates so much of the tedious grunt work.
The Power to Edit and Compare
Seeing a problem is one thing, fixing it is another. Lilac’s interface allows you to directly edit and compare fields. You can see two similar documents side-by-side, make changes, and tag data for removal or modification. It closes the loop between analysis and action, which a lot of other tools just don't do.
Getting Started with Lilac: Is It for You?
Getting it up and running is as simple as a `pip install lilac`. If that command scares you, then this tool might not be for you just yet. It’s designed for folks who are comfortable in a Python environment. This isn’t a completely no-code, drag-and-drop solution for business analysts. It requires a bit of technical skill to really unlock its potential.
Some might argue the documentation could be a little more fleshed out, and that's a fair point for a growing open-source project. However, the potential here is enormous. And with the recent Databricks acquisition, you can bet that support, integration, and development are about to go into overdrive. That move provides a ton of stability and a clear sign that Lilac is becoming a core part of the modern MLOps stack.
"Lilac is an incredibly powerful tool for data exploration and quality control... It is a critical part of our data curation pipeline." – Jonathan Talmi, Leader of Instruction Quality @ Cohere
What About the Price Tag?
This is the easiest part to talk about. It’s free. Lilac is an open-source project. There's no pricing page because you don't need one. This is a massive advantage over some of the behemoth, walled-off enterprise platforms that charge an arm and a leg for similar (and sometimes, less powerful) features. The value here is almost absurdly high.
FAQs about Lilac AI
- What is Lilac primarily used for?
- Lilac is used by AI developers and data scientists to explore, analyze, and clean text datasets for training Large Language Models (LLMs). Its main goal is to improve data quality to build better, more reliable AI models.
- Is Lilac really free to use?
- Yes, it is. Lilac is an open-source project, meaning it's free to download, use, and modify. You can install it directly using Python's package manager.
- Who should use Lilac?
- It's best suited for people with some technical background, like data scientists, ML engineers, and AI researchers, who are comfortable working with Python and managing their own development environments.
- Can Lilac handle large datasets?
- Absolutely. It's designed for speed and can process and analyze datasets with millions of rows, making it suitable for serious, large-scale projects.
- What does the Databricks acquisition mean for Lilac's future?
- It's a very positive sign. It provides financial stability, resources for faster development, and likely deeper integration into the popular Databricks platform, solidifying Lilac's place as a key tool in the data and AI ecosystem.
Final Thoughts: The Focus is Shifting
For a while there, the AI world was all about model architecture and parameter counts. But the pendulum is swinging back. We're finally re-learning that incredible models are built on incredible data. It's not as sexy, but it's the truth.
Tools like Lilac are at the forefront of this shift. They empower individual developers and teams to take control of their data in a way that just wasn't easy before. It's fast, powerful, and thanks to its open-source nature, accessible to everyone. If you're serious about building quality LLMs, you need to be serious about your data. And you should probably go and `pip install lilac` right now.