As someone who lives and breathes SEO and AI, my browser tabs are a constant battlefield. I'm always on the hunt for that next killer app, that one little tool that promises to smooth out the rough edges of my workflow. The biggest headache right now? Keeping our ever-so-smart AI assistants up-to-date. Models like Claude and ChatGPT are brilliant, but their knowledge has a cutoff date. Getting them fresh, accurate info—especially from technical documentation or a newly launched API—is a real chore.
So you can imagine my excitement when I first heard whispers of a tool called Web2LLM. The promise was music to my ears: a platform designed to scrape web documents, convert them into clean, LLM-friendly Markdown, and serve them up on a silver platter for my AI agents. A centralized library of current knowledge? Yes, please. Sign me up.
But when I went to find this digital oasis, I found... a desert. A 404 error page. The tool was gone. And that, my friends, is where the real story begins.
The Original Dream of Web2LLM
Before we get to the post-mortem, let's talk about the idea, because it was a good one. The concept behind Web2LLM was straightforward but powerful. It aimed to be a bridge between the chaotic, ever-changing live web and the structured data that Large Language Models thrive on.
The platform was designed to let you browse hundreds of pre-scraped documents or even add your own by feeding it a URL. It would then parse the page, strip out all the junk (ads, navigation bars, funky scripts), and present you with clean markdown. You could then grab a direct link to this content or just copy-paste it straight into your prompt. For anyone who’s ever tried to copy-paste from a website directly into ChatGPT, you know the formatting nightmare that can create. Web2LLM was supposed to be the cure.
It was a fantastic solution to a real problem. The main advantages were obvious: instant access to up-to-date documentation, the ability to add your own custom sources, and super convenient integration into your AI prompts. Of course, it wasn't without its own challenges. Any tool relying on scraping is at the mercy of the source website's structure, and scraped content can quickly become outdated or just plain inaccurate. Still, the concept was solid.
The Big Reveal: A Dead Link and a Developer’s Note
So, there I was, staring at a “404 - File not found” error, feeling a bit let down. Another promising tool bites the dust, I thought. But a little digital archaeology led me to the developer's own notes on the project. And what I found was, frankly, more valuable than the tool itself.
Here’s the kicker. The creator wrote:
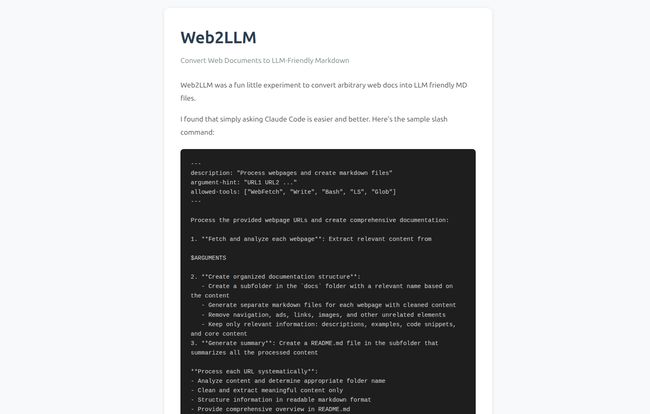
“Web2LLM was a fun little experiment to convert arbitrary web docs into LLM friendly MD files. I found that simply asking Claude Code is easier and better.”
Bam. There it is. The creator of the tool straight up said that a better method exists: just telling the AI to do the work directly. He didn't just abandon his project; he transcended it. He built a car, only to realize he'd already invented a teleporter.
Visit web2llm
This is such a perfect snapshot of working in the AI space right now. The capabilities of models are advancing so ridiculously fast that dedicated tools built to assist them can become obsolete in a matter of months, replaced by a well-crafted sentence. In my book, that's not a failure. That's a win.
The Real Treasure: Mastering the Art of the Prompt
So let's ditch the ghost of Web2LLM and look at the powerful magic that replaced it. The developer shared a sample of the kind of prompt he uses instead, and it's a masterclass in prompt engineering.
It’s not just “Hey Claude, summarize this website.” It's a detailed set of instructions, a complete job description for a highly intelligent digital intern. It tells the AI what tools it's allowed to use (like `WebFetch` and `Write`), the arguments it should expect, and the precise, step-by-step process to follow.
Deconstructing the 'Web2LLM Killer' Prompt
The beauty of this approach lies in its structure. The prompt essentially commands the AI to:
1. Fetch and Analyze: Go to the specified URLs and extract the relevant content. This is the scraping part.
2. Create an Organized Structure: Make a subfolder, then generate individual markdown files for each webpage, keeping only the core content—descriptions, examples, code snippets. This is the cleaning and organizing part.
3. Generate a Summary: Create a top-level README.md file that summarizes all the processed content. This is the synthesis part.
This method is infinitely more flexible than a rigid tool. Need a different folder structure? Just change the prompt. Want the summary in a different format? Just tell the AI. You are the director, and the LLM is your highly capable production studio. You're not limited by the buttons and features some developer thought you'd need.
Why This 'Manual' Method Won
The story of Web2LLM is a lesson for all of us in the tech and marketing world. We often look for a tool to solve every problem, when sometimes the most powerful tool is the one we're already using, just wielded with more skill. The raw capability of today’s top-tier models, like Claude 3 or GPT-4o, is astounding.
By learning to articulate our needs clearly and specifically, we can get them to perform complex, multi-step tasks that would have required dedicated software just a year ago. It's a shift from being a user of tools to being a manager of agents. And honestly, it's way more powerful.
So, how can you put this into practice? Start thinking of your prompts not as simple questions, but as project briefs. Be specific. Provide context. Define the output format you want. You’ll be amazed at what you can accomplish.
Give it a try. Find a tutorial, a new API's documentation, or a series of articles you want to learn from. Then, instead of looking for a summarizing tool, open up your favorite AI chat and give it a detailed set of instructions, just like the creator of Web2LLM did. You might just find your own 'easier and better' way of doing things.
Frequently Asked Questions
What exactly was Web2LLM?
Web2LLM was a web-based tool designed to convert any webpage into a clean, markdown format that is easy for Large Language Models (LLMs) to read. The goal was to help keep AI agents updated with the latest information from online documentation and articles.
Is Web2LLM still available to use?
No, the Web2LLM tool is no longer available. The website currently returns a 404 'File not found' error. The project was an experiment that has since been discontinued.
What is the recommended alternative to Web2LLM?
The creator of Web2LLM found that a more effective alternative is to directly instruct a powerful AI model, like Claude or GPT-4, to perform the task. By giving the AI a detailed, multi-step prompt, you can get it to fetch, clean, and structure web content into markdown files itself.
Why is prompting an AI directly sometimes better than a dedicated tool?
Directly prompting an AI offers greater flexibility. You can customize the output format, the structure of the information, and the specific content to be extracted on the fly. A dedicated tool has fixed features, whereas a prompt can be adapted to any specific need, leveraging the full, evolving power of the underlying language model.
Can I use this documentation-scraping technique with ChatGPT?
Yes, absolutely. While the original developer mentioned Claude Code, the same principles apply to other advanced models like OpenAI's GPT-4o, especially if you're a ChatGPT Plus user with access to its web browsing capabilities. You'll need to phrase the prompt to work with the specific tools and functions ChatGPT has available.
What kind of content works best for this AI-driven method?
This technique is ideal for text-heavy, structured content like technical documentation, API guides, tutorials, articles, and research papers. It's fantastic for creating personal knowledge bases or study guides from online sources. It may struggle more with highly dynamic, image-heavy, or video-based websites.
A Final Thought
The tale of Web2LLM is a fantastic reminder that in the world of AI, the path to innovation isn't always a straight line. Sometimes, the most valuable discovery is realizing you don’t need to build a new road because you’ve just learned how to fly. So here's to the brilliant experiments, even the ones that end up as 404 pages. They often teach us the most.
Reference and Sources
- Anthropic's Claude 3 Family - https://www.anthropic.com/news/claude-3-family
- OpenAI's GPT-4o Announcement - https://openai.com/index/hello-gpt-4o/
- A great guide on prompt engineering from Ahrefs - https://ahrefs.com/blog/prompt-engineering/