For years, I’ve been in the trenches of SEO and traffic generation, and I've watched the AI wave build from a ripple to a full-blown tsunami. It's exciting, right? We've got models that can write, create stunning images, and even generate video. The problem? Actually using these things in a real-world application has been, to put it mildly, a pain in the rear.
You either become an unwilling part-time DevOps engineer, wrestling with CUDA drivers and Docker containers, or you resign yourself to paying eye-watering fees to the big cloud providers. I can't count the number of times I've seen a promising AI startup get kneecapped by their own infrastructure costs. It's a dark art, and the barrier to entry has been ridiculously high.
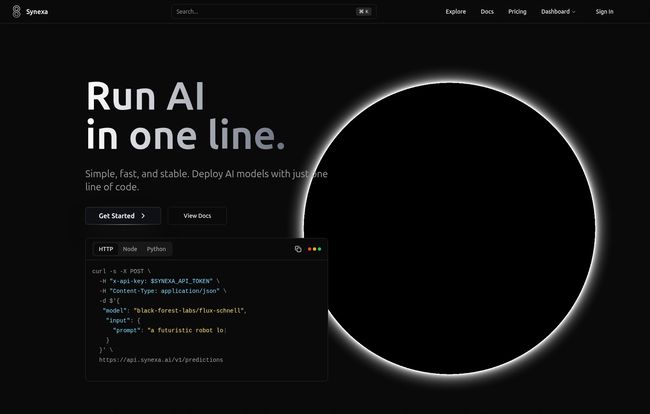
So when I stumbled upon a platform called Synexa AI, my inner cynic was on high alert. Their headline? "Run AI in one line." Sure, I thought. And I've got a bridge to sell you. But the more I looked, the more my cynicism started to... well, dissolve. This thing might actually be the real deal.
Visit Synexa AI
So, What Exactly Is Synexa AI?
Strip away the marketing jargon, and Synexa AI is essentially a serverless platform built specifically for running AI models. Think of it like this: You know how services like Vercel or Netlify made deploying a website as easy as a git push? Synexa aims to do the same thing for complex AI inference. It takes the whole messy business of managing GPUs, scaling servers, and optimizing environments off your plate.
Instead of provisioning a server, installing dependencies, and praying to the tech gods, you just... call their API. You give it the model you want to run and your prompt, and it gives you back the result. That's it. It’s the abstraction layer I think we’ve all been secretly wishing for.
The One-Liner That Actually Changes Everything
Let's focus on that "one line of code" promise for a second. This isn't just a catchy phrase. It represents a fundamental shift in workflow. For a developer or a small team, the time difference between fiddling with infastructure for a week versus writing a single API call is monumental. It's the difference between launching this quarter and launching... maybe next year?
Look at their example:
curl -s -X POST \ -H "Authorization: Bearer $SYNEXA_API_TOKEN" \ -H "Content-Type: application/json" \ -d '{ "model": "black-forest-labs/flux-schnell", "prompt": "a futuristic robot in space" }' \ https://api.synexa.ai/v1/predictionsThat’s it. That’s the whole deployment process. It feels almost anticlimactic, but that's the point. The magic is in what you don't have to do. You don't have to worry if the server will crash if you get a sudden spike in traffic. Synexa’s architecture is built to automatically scale up to handle the load and—this is the beautiful part—scale back down to zero when it's idle. You literally don't pay for a single second of compute you're not using.
Let's Talk Money: Breaking Down the Cost Savings
This is where my ears really perked up. Cool tech is one thing, but affordable tech is what changes the game. Synexa is refreshingly transparent with its pricing, and frankly, it's aggressive. They seem to know that cost is the biggest roadblock for most people, and they've tackled it head-on.
Pay-per-Output Pricing
For many popular models, you're not even renting hardware; you're just paying for the result. This is brilliant. It makes your costs predictable and directly tied to your usage. For example, generating an image with Stable Diffusion XL is just $0.002. They claim this is a 50% savings over other providers, and from what I've seen, they're not exaggerating. Creating a video with the Wan 2.1 Video Model costs $0.20 per video, again, half of what you might pay elsewhere. This model-based billing simplifies everything, you dont have to guess how long a job will take or what GPU it needs.
The Bare Metal GPU Costs
If you do need dedicated access to specific hardware, their per-second billing is a lifesaver. Let's get into the weeds here, because the numbers are impressive. I've put their hardware prices in a little table to show you what I mean. They're comparing themselves to platforms like Replicate and Fal.ai, and the difference is stark.
| Hardware | Synexa Price (per hour) | Comparable Platform Price (per hour) |
|---|---|---|
| Nvidia RTX 3090 | $0.43 | N/A |
| Nvidia A100 (80GB) | $2.49 | $5.04 (Replicate) / $3.99 (Fal.ai) |
| Nvidia H100 | $2.99 | $5.49 (Replicate) / $4.50 (Fal.ai) |
That H100 price is wild. Getting access to the latest and greatest Nvidia silicon for under $3/hour, billed by the second, and with zero management overhead? That's not just a good deal; it's a paradigm shift for anyone who isn't a massive corporation.
Performance and Power Under the Hood
Okay, so it's simple and cheap. But is it any good? A lot of "cost-effective" solutions cut corners on performance. I was pleasantly surprised to see this doesn't seem to be the case with Synexa.
Not Just Cheap, But Fast
They boast about their "blazing fast inference engine," claiming it's up to 4x faster on some models. While I always take marketing benchmarks with a grain of salt, the underlying components check out. They're running a global infrastructure with top-tier GPUs like the A100s and H100s. This means low latency and high throughput, which are critical for any user-facing AI application. Nobody wants to use an app where they have to wait 30 seconds for an image to generate. Speed is a feature, and it looks like Synexa delivers.
A Buffet of AI Models
Another thing I love is their extensive model collection. They have over 100 production-ready models ready to go out of the box. This isn't just a BYOM (Bring Your Own Model) platform; it's a curated library. You get access to cutting-edge stuff like Black Forest Labs' FLUX.1 (in its various 'dev', 'schnell', and 'pro' flavors), Stable Diffusion XL, video models, and even 3D models like Hunyuan 3D. It feels less like an empty garage where you have to bring your own tools and more like a fully-stocked workshop.
Is Synexa AI Right for You?
So, who is this for? In my opinion, the sweet spot is massive. If you're an indie developer, a startup, or even a team within a larger company that wants to rapidly prototype and launch an AI feature without getting bogged down in red tape and budget meetings, Synexa is a godsend. It lowers the financial and technical barrier to entry so dramatically that it opens up a world of possibilities.
Some might argue that you lose a degree of control compared to managing your own hardware on AWS or GCP. And that's true. If you have a highly esoteric use case with a custom-compiled model that requires specific kernel-level tweaks, this might not be the right fit. But for the 95% of use cases out there? The trade-off for speed, simplicity, and cost is a no-brainer.
Frequently Asked Questions about Synexa AI
How does Synexa's 'scale to zero' feature actually work?
It means that when your application isn't receiving any API requests for a specific model or hardware, Synexa's system automatically de-allocates the resources. You're not paying for an idle GPU just sitting there. The moment a new request comes in, it spins up the necessary resources instantly to process it. This is the core of their cost-effective, serverless model.
What kinds of AI models can I run on Synexa?
They offer a huge range of models, including text-to-image (like Stable Diffusion and FLUX.1), video generation (Wan 2.1), 3D model generation (Hunyuan 3D), image captioning, and more. Their library is constantly growing, and you can browse the full collection on their site.
Is Synexa AI suitable for large-scale production applications?
Yes, absolutely. The platform is designed for scale. The automatic scaling infrastructure means it can handle everything from a few requests a day to millions. Since you're using a stable, managed API, it's arguably more reliable for production than a self-managed setup, especially for smaller teams.
How does the pricing compare to AWS SageMaker or Google Vertex AI?
It's generally much simpler and more cost-effective for most common use cases. While major cloud providers offer incredible power, their pricing can be complex and expensive, often with hidden costs for data transfer, storage, and idle time. Synexa's pay-per-use and per-second billing is far more transparent and usually cheaper for inference tasks.
What makes Synexa different from other platforms like Replicate?
While they operate in a similar space, Synexa's main differentiator appears to be cost. As shown on their own pricing page, they are directly competing with platforms like Replicate and Fal.ai by offering significantly lower prices for the same hardware and model outputs. Their focus is on being the most cost-effective serverless AI provider.
My Final Takeaway
I’ve been around this block a few times, and I’ve seen a lot of platforms promise to revolutionize development. Most of them are just hype. Synexa AI feels different. It’s not just a tool; it’s a solution to a problem that has plagued the AI space for years. It makes powerful AI accessible, affordable, and, dare I say, fun to work with again.
By removing the friction of deployment and the fear of a five-figure cloud bill, they’re empowering a new generation of builders. And as someone who loves seeing cool new things get made, I’m genuinely excited to see what people create with this. It feels like we're finally getting the keys to the car, without having to build the engine from scratch first.