PDFs are the necessary evil of the digital world. We need them for invoices, reports, legal documents, you name it. But getting the information out of them? That's a whole other story. I’ve spent more hours of my life than I care to admit with two screens open, painstakingly copy-pasting line items from a PDF invoice into an Excel sheet. It's tedious. It's soul-crushing. And my accuracy after the third hour and second cup of coffee? Let's just say it's… questionable.
So, when I stumbled upon a tool called PDFMerse, which claimed to use AI to automatically rip structured data from PDFs, my inner SEO and data geek sat up straight. Another AI tool promising to solve all our problems? I've seen a few of those. But this one felt a bit different. It wasn't just about OCR; it was about understanding the structure of the data. I had to give it a spin.
Visit PDFMerse
So, What is PDFMerse Anyway?
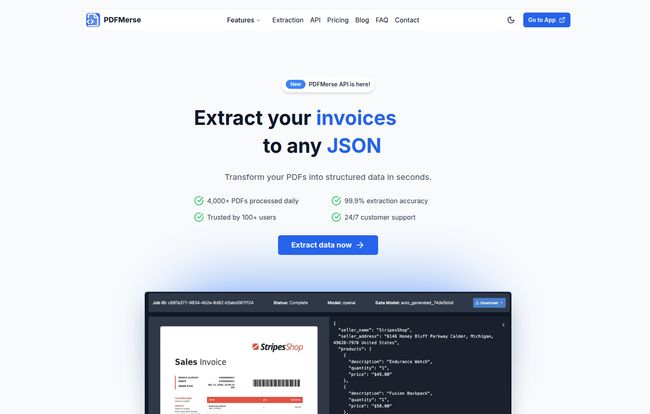
At its core, PDFMerse is an AI-powered data extraction tool. You feed it a PDF—think a messy, multi-page invoice or a scanned contract with handwritten notes—and it gives you back clean, structured data in a format your applications can actually use, like JSON. It’s designed to be the bridge between those static, locked-down documents and dynamic, actionable information.
It’s not just a simple text scraper. The AI part is what's interesting. It's built to understand context, which means it knows the difference between a “seller_name” and a “line_item_description.” For anyone who has tried to build their own parser, you know that’s the hard part. It even claims to handle handwritten text and multiple languages, which frankly, sounds kinda magical.
The Agony of Manual Data Entry is Real
I once had a freelance gig where I had to process about 200 scanned receipts for a small business's quarterly tax filing. Two hundred. Some were faded, some were crumpled, one had a suspicious coffee stain that obscured the total amount. It took me the better part of a weekend, and I’m pretty sure I still messed up a few entries. My brain felt like mush. The client was happy, but I vowed never again.
This is the exact pain point PDFMerse is built to solve. It’s for the finance teams drowning in invoices, the marketing agencies trying to pull data from client reports, the legal aides sifting through contracts, and the developers who get tasked with building a tool to “just quickly grab the data from these PDFs.” It’s a universal problem, and automation is the only sane solution.
How PDFMerse Aims to Change the Game
Okay, so it talks a big game. But what does it actually do? I dug into its features, and a few things really stood out to me from a practical, day-to-day use perspective.
Automated Extraction on Autopilot
The main event, of course, is the automated extraction. You give it a PDF, and its AI gets to work identifying and pulling out the key information. It's not just about turning the whole thing into a wall of text. It intelligently creates data models, meaning it organizes the extracted info into a logical structure. For an invoice, this means it separates the vendor details, line items, taxes, and total amount into distinct fields. This is a massive time-saver compared to manual entry or basic OCR tools.
It Even Reads Your Doctor's Handwriting?
Well, maybe. The website boasts support for handwritten text, and this is a feature that really caught my eye. While its accuracy will obviously depend on how legible the handwriting is (my own chicken-scratch might pose a challenge), the ability to process scanned forms with filled-in fields is huge. Add to that its multi-language support, and you have a tool that’s genuinely flexible for global or diverse business operations. It’s a far cry from older tools that would fall apart if they saw an accent mark or a cursive signature.
Clean, Structured Data... Guaranteed
Here’s something my developer friends will appreciate. PDFMerse doesn’t just dump text on you. It guarantees structured output, primarily in JSON. Why is this a big deal? Because it means you can reliably feed this data directly into your other software, databases, or analytics platforms without a messy, error-prone clean-up step. Their site also says CSV and Table formats are coming soon, which will be great for the spreadsheet warriors among us. They even have built-in validation processes to check the integrity of the data it extracts.
For the Devs: A RESTful API That Just Works
While you can use their web interface to process documents, the real power for scaling your operations comes from the PDFMerse API. It’s a straightforward RESTful API. This means you can integrate PDFMerse’s extraction brain directly into your own applications. Imagine an accounting software that automatically processes any uploaded invoice, or a CRM that pulls contact info from uploaded business cards. The API is designed for high volume and performance, so you can build some seriously efficient automated workflows.
Let's Talk Money: The PDFMerse Pricing Tiers
Alright, the all-important question: what does it cost? The pricing structure is tiered, which I appreciate. It lets you start small and scale up as your needs grow. Here's a quick breakdown as I see it:
| Plan | Price | Who It's For | Key Features |
|---|---|---|---|
| Free | $0/month | Individuals or anyone wanting to test the waters. | 10 page extractions/month, JSON output. |
| Basic | $5/month | Small teams or freelancers with light, consistent needs. | 100 pages/month, API access, JSON output. |
| Professional | $29/month | Growing businesses and developers who need more power. | 1,000 pages/month, multiple formats (soon!), custom data models, priority support, 2,000 API credits. |
| Enterprise | $79/month | Large organizations with high-volume, critical workflows. | Unlimited pages, dedicated support, custom integrations, 20,000 API credits. |
Honestly, the free plan is perfect for seeing if it works on your specific type of documents. The Professional plan at $29/month seems like the sweet spot for most serious users—you get a ton of pages, the advanced features, and enough API credits to build some cool stuff.
The Good, The Bad, and The PDF
No tool is perfect, right? Here’s my honest take on the pros and the potential drawbacks based on what I've seen.
What I Really Like
The time savings are the most obvious win. Turning hours of manual data entry into seconds is a no-brainer. I also love the focus on structured data, which is a huge step up from basic OCR. The API is a massive plus for anyone looking to automate at scale, and the fact that it tackles tricky things like multiple languages and even handwriting shows some serious ambition.
A Few Things to Keep in Mind
The platform itself admits that accuracy can vary depending on the quality and complexity of the PDF. A clean, machine-generated invoice will probably hit that 99.9% accuracy mark they advertise. A blurry, scanned-on-a-potato document? Your mileage may vary. Also, to get the really cool features like custom data models and multiple output formats, you do need to be on a paid plan, which is pretty standard for SaaS tools like this.
Frequently Asked Questions
What types of PDFs can PDFMerse handle?
It's designed for a wide range, including invoices, receipts, contracts, bank statements, and legal documents. Its ability to handle different layouts and even handwritten text makes it quite versatile.
How accurate is the data extraction?
PDFMerse advertises up to 99.9% accuracy. In my experience with similar tools, this is likely for clear, high-quality documents. For more complex or lower-quality PDFs, you should probably build in a quick human review step, but it will still be worlds faster than full manual entry.
What output formats are available?
Currently, the primary output is structured JSON. The company says Text, CSV, and Table formats are on the way, which will make it even more accessible for non-developers.
Is my data secure?
This is a big one. PDFMerse states their platform is secure and reliable. For any business handling sensitive information (like financial or personal data), it’s always a good idea to review their specific data security and privacy policies, but they seem to take it seriously.
Can I create my own data extraction models?
Yes! This is a feature available on the Professional and Enterprise plans. It allows you to train the AI to understand your specific, unique document layouts for even better accuracy.
Final Thoughts: Is PDFMerse Worth It?
After digging in, I'm genuinely impressed. PDFMerse isn't just another OCR tool. It's an intelligent automation platform aimed at solving a very real, very annoying business problem. It’s a tool that gives back the one thing we can never get more of: time.
If you or your team are still stuck in the cycle of manually copying data from PDFs, you owe it to your sanity to give PDFMerse a try. Start with the free plan, throw one of your most annoying PDFs at it, and see what happens. You might just find that your toxic relationship with PDFs is finally over.