I spend my days swimming in the chaotic currents of SEO, CPC, and the latest tech trends. You get used to the noise. Every other day there’s a new “GPT-killer” or a platform that promises to revolutionize, well, everything. Most of it is just marketing fluff. But every once in a while, you stumble upon something that makes you lean in a little closer. Something that sounds too good to be true, yet too specific to be fake.
That’s exactly how I felt when I first heard whispers of HyperLLM. The claims are audacious: a new breed of Small Language Model (SLM) that offers instant fine-tuning and training, at a cost that’s supposedly 85% less than the big players. My first thought? “Yeah, right.” My second thought? “I have to know more.”
But my investigation hit a very strange, very modern roadblock. When I went to check out their website, hyperllm.org, I wasn’t greeted by a slick landing page or a GitHub repository. I was greeted by this:
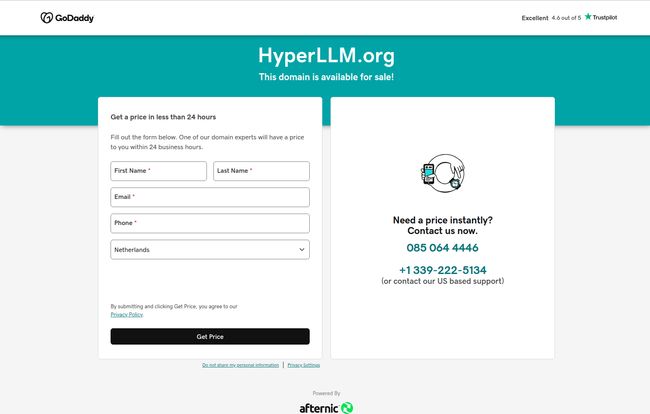
Visit HyperLLM
Yep. The domain is for sale on GoDaddy. A fascinating, if not slightly concerning, start. Is this an unlaunched project in stealth mode? A brilliant idea that ran out of runway? Or just a very, very elaborate bit of vaporware? Honestly, I don't have the answer, but the technology it describes is too interesting to ignore. So, let’s put on our detective hats and analyze the clues we have about what HyperLLM is… or what it was meant to be.
So, What is HyperLLM Supposed to Be?
Putting the strange domain situation aside for a moment, let’s talk tech. At its core, HyperLLM is described as a new type of model called a 'Hybrid Retrieval Transformer' or HRT. It’s a mouthful, I know. Think of it like this: traditional large language models like GPT-4 are like a massive, static library. They know a ton of information, but it’s all from before their training cut-off date. To teach them new things (a process called fine-tuning), you have to go through a costly and time-consuming process of basically rebuilding a section of the library.
HyperLLM’s approach sounds different. It combines a smaller, more agile model with a system called HyperRetrieval. Instead of retraining the model, it instantly pulls in new, real-time information when it needs it. It’s less like rebuilding the library and more like giving the librarian a super-fast internet connection and a perfect memory. This method is often compared to Retrieval-Augmented Generation (RAG), a technique many of us in the space are already using. But HyperLLM claims its architecture is zero-latency, which is a very bold claim indeed.
The Promise of Instant Fine-Tuning
This “instant fine-tuning” is the real headline-grabber. For anyone who’s tried to fine-tune a model, you know the pain. It takes time, a huge dataset, and a credit card that isn’t afraid of heights. The idea of skipping that entire process is… well, it’s the holy grail for many developers and startups. If HyperLLM can actually pull real-time data into its context without a formal “training” period, it changes the game. Your AI assistant could be aware of news that broke seconds ago, or your customer service bot could have immediate access to a new product’s specs without any downtime.
Going Serverless and Decentralized
Another piece of the puzzle is the claim of being “truly server-less and decentralized.” In the age of vendor lock-in with giants like Amazon, Google, and Microsoft, this is music to my ears. A decentralized model means you’re not tethered to a single company’s infrastructure. It suggests more control, potentially better privacy, and getting rid of those pesky recurring storage charges for your vector databases. I’m a big fan of anything that gives power back to the creators, and this philosophy is definitely a step in the right direction.
Let’s Talk Money: The 85% Cost Reduction Claim
Okay, let’s get to the number that made everyone sit up: 85% less cost than top LLMs. That’s not a small discount; that’s a complete disruption. Where does this saving come from? Primarily, it seems to come from two places:
- No Training/Tuning Costs: As mentioned, fine-tuning is expensive. Removing that entire step from the equation would slash budgets dramatically.
- No Recurring Storage Charges: The serverless architecture means you're not paying a monthly fee just to keep your data embeddings on standby. This is a subtle but significant long-term saving.
It’s hard to verify this claim without a live product or a pricing page (which, as we know, doesn’t exist). But theoretically, the logic holds up. The most expensive parts of running custom AI are the computational power for training and the persistent storage. If HyperLLM’s architecture genuinely sidesteps these, then massive savings aren’t just possible, they’re probable. It would make powerful, customized AI accessible to a much broader audience, from indie hackers to small businesses who are currently priced out of the market.
The Downsides and the Lingering Mystery
Of course, there are always catches. The information I dug up listed a couple of cons. One is practical: white-labeling API URLs is an invite-only feature. That's a standard limitation for a new service finding its feet. The other one, however, is… weird. It’s listed as “Potential limitations for achieving singularity (unspecified).” I had to laugh at that one. It’s either a tongue-in-cheek joke from a developer or a placeholder of epic proportions. Either way, I don’t think we need to worry about this thing becoming Skynet just yet.
The real downside, the big red flag, is the domain name. Why build something this potentially revolutionary and not secure the dot-org? It leads to a few possibilities:
- It was a project that was abandoned. The creators built the concept, maybe even a prototype, but couldn't get funding or lost interest.
- It's a rebrand. The technology might live on under a different name, and they just let the old domain expire.
- It's in deep, deep stealth. Maybe they operate under a different name and this was a decoy. A bit conspiratorial for my taste, but not impossible.
My gut tells me it’s likely the first option. A brilliant idea that hit a wall. It’s a common story in Silicon Valley and beyond. But the ideas themselves—the Hybrid Retrieval Transformer, the zero-latency RAG, the focus on cost-efficiency—are now out in the world. And good ideas have a habit of resurfacing.
Frequently Asked Questions About HyperLLM
What are Hybrid Retrieval Transformers (HRTs)?
HRTs are a type of AI model architecture that combines a smaller language model with a real-time information retrieval system. Instead of storing all its knowledge internally, it can quickly “look up” new information as needed, allowing it to stay current without constant retraining.
Is HyperLLM a real, usable product?
As of right now, it doesn't appear to be publicly available. The fact that its primary domain (`hyperllm.org`) is for sale suggests the project is either inactive, abandoned, or operating under a completely different name. It's best to think of it as a concept or a case study for now.
How is this different from standard RAG (Retrieval-Augmented Generation)?
It seems to be an evolution of RAG. The key differentiator is the claim of “zero-latency” retrieval and a truly serverless architecture. While standard RAG also fetches external data, it can introduce latency. HyperLLM's “HyperRetrieval” system implies an almost instantaneous process, which would be a significant technical achievement.
What does “Exthalpy” mean in the context of HyperLLM?
According to the documentation, Exthalpy is the name given to the variable used for hyperparameter control. It’s essentially a clever branding for the set of controls that would allow a developer to tweak the model's performance, like adjusting the balance between speed and accuracy.
My Final Take: A Glimpse of the Future?
So, where does that leave us with HyperLLM? It’s a ghost ship. A tantalizing promise with no one at the helm. And yet, I can't shake the feeling that this is important.
Whether HyperLLM itself ever sees the light of day is almost beside the point. The concepts it champions are the direction the industry is heading. The future of AI isn’t just about building bigger and bigger models; it’s about building smarter, more efficient, and more accessible ones. We need solutions that are fast, affordable, and constantly up-to-date. We need systems that democratize this incredible technology.
HyperLLM provided a blueprint for what that could look like. It’s a compelling, albeit incomplete, story. And I’ll be keeping an ear to the ground, waiting to see if these brilliant ideas pop up again, hopefully with a registered domain name next time.
References and Sources
For further reading on the concepts discussed in this article, please see the following resources:
- GoDaddy Auction Page for hyperllm.org
- What is Retrieval-Augmented Generation (RAG)? - An overview from Amazon Web Services.
- Not All Language Models Need to be Large - A discussion on the rise of Small Language Models (SLMs) from Hugging Face.