For the last couple of years, building with large language models has felt a bit like alchemy. You throw a dash of prompt here, a pinch of context there, whisper a secret incantation (your API key), and hope for gold. Sometimes you get it. Other times... you get a very confident, very wrong, lead-like output. And the worst part? Replicating the 'gold' consistently across your entire application feels like trying to build a skyscraper on a foundation of Jell-O.
I've been in the SEO and traffic game for years, and I’ve watched countless trends come and go. But the speed at which Generative AI has taken over is something else. We've all been scrambling to integrate it, to build smarter tools, better content engines, and more intuitive agents. The problem is, the tooling for validating this new tech has been lagging way behind the hype. We're building Ferraris with bicycle maintenance kits. We're using spreadsheets and gut-feelings to judge mission-critical AI components. It's organized chaos at best.
So, when a tool like EvalsOne pops up on my radar, claiming to bring order to this chaos, my professional curiosity gets the better of me. It bills itself as a one-stop evaluation platform for GenAI, designed to streamline the whole messy process. But is it just another drop in the ocean of dev tools, or is it the life raft we’ve been waiting for? I decided to take a look.
So, What's EvalsOne All About?
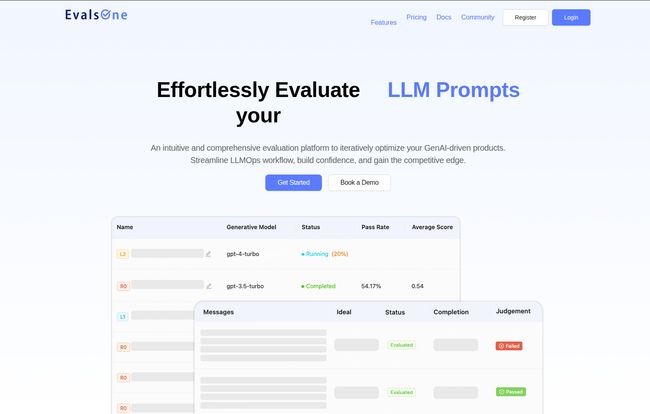
At its core, EvalsOne is a platform designed to put a leash on your LLMs. It’s built to give developers a structured, repeatable, and measurable way to test and improve their AI applications. Think of it less as a simple playground for writing prompts and more like a full-blown science lab for your AI. It’s not just for testing a single prompt, but for evaluating the whole system it lives in.
The platform focuses on three main targets:
- LLM Prompts: The most basic unit. How good is your prompt at getting the model to do what you want?
- RAG Flows: Retrieval-Augmented Generation is huge right now. EvalsOne lets you test how well your system retrieves the right information and uses it to generate a good answer. This is critical for avoiding hallucinations.
- AI Agents: For more complex, multi-step tasks, you can evaluate the entire agent's performance from start to finish.
It’s designed to fit right into the LLMOps workflow, taking you from the initial development phase all the way through to monitoring the app in production. This lifecycle approach is what first caught my eye. It's ambitious.
Visit EvalsOne
My Favorite Features After Kicking the Tires
Okay, let’s get into the good stuff. After poking around the platform's features (based on their site, since I haven't booked a full demo... yet), a few things really stood out to me as a practitioner who has felt the pain of AI development.
A Unified Toolbox for Dev, Test, and Production
The first thing that jumps out is the blend of Automated and Manual evaluation. Automated checks are great for speed and scale. You can set up rule-based evaluators (e.g., “Does the output contain a specific keyword?”) or even use another LLM as a judge (a fascinating, slightly meta concept). But we all know that sometimes, you just need a human to look at something and say, “Yeah, that’s a good answer,” or “Nope, that’s technically correct but tonally a disaster.”
EvalsOne bakes this human feedback loop right into the platform. This is a game-changer. No more exporting results to a spreadsheet and emailing it around the team for subjective scores. It’s all integrated. This closes the gap between what the machine thinks is a good output and what your users feel is a good output.
The Iterative “Run, Fork, Optimize” Loop
I absolutely love this concept. The UI shows a workflow where you can run an evaluation, see the pass rate, and then “fork” that run to try a new variation. It’s essentially Git for prompt engineering. You can tweak a prompt, change a model parameter, or use a different model entirely, and then run it again to see a direct A/B comparison.
This iterative process is how real improvement happens. It turns prompt design from a dark art into a data-driven science. You have a history, you have versioning, and you have clear metrics. For any team trying to justify their work to management, this is pure gold. “Look, with this new prompt, our accuracy score went up by 12%.” That’s a conversation every product manager wants to have.
Seriously Impressive Model Integration
Vendor lock-in is a real fear in the AI space. It’s great to see that EvalsOne seems to be model-agnostic. They list support for all the big players: OpenAI’s GPT series, Anthropic’s Claude, Google’s Gemini, and open-source champs like Llama. But the real kicker? The ability to connect to locally-run models via Ollama or custom APIs, and even add your own private, fine-tuned models.
This is huge. Companies spending a fortune on proprietary models need a way to benchmark them against commercial ones, and EvalsOne provides that framework. It’s a smart, forward-thinking feature that shows they understand their target market.
Those Out-of-the-Box (and Custom!) Evaluators
Starting from scratch is a pain. EvalsOne gives you a set of pre-built evaluators for common scenarios. Things like `Fuzzy match`, `JSON output check`, and crucially, `RAG content precision` and `RAG context recall`. If you've ever built a RAG system, you know those last two are the holy grail of metrics. How much of the right context did we pull, and did we miss anything important?
But the real power lies in extensibility. The platform allows you to define your own custom evaluation metrics. Every application is unique, and sometimes a generic `pass/fail` isn’t enough. You might need to measure for a specific tone, a certain data format, or a complex business rule. The ability to build your own yardstick is a sign of a mature, flexible tool.
Who Is This Platform Actually For?
Let's be clear, this isn't a tool for the casual hobbyist trying to write better ChatGPT prompts for their D&D campaign. EvalsOne is squarely aimed at professional teams building, deploying, and maintaining generative AI products. The language, the features, the entire LLMOps workflow integration—it all screams B2B and enterprise.
This is for the AI engineer who is tired of running evaluations in a Jupyter notebook. It's for the ML Ops team that needs to integrate AI testing into their CI/CD pipeline. It's for the Product Manager who needs to see concrete data on whether the latest AI feature is actually better than the last one. If you're having serious conversations about RAG pipeline optimization or agentic workflow reliability, you're the target audience.
The Elephant in the Room... The Pricing
So, how much does this magical platform cost? Well, that’s the million-dollar question. The website doesn't have a pricing page. Instead, it has two buttons: “Get Started” and “Book a Demo.”
In my experience, this almost always means one thing: it’s not cheap. This is the classic enterprise sales model. The price is likely customized based on your team size, usage volume, and required support level. While I always prefer transparent pricing, I get it. A tool this specialized requires a conversation to understand the customer's needs. So, don't expect a simple monthly subscription tier. Be prepared to talk to a sales rep. It's a bit of a downside for smaller teams who just want to try it out, but it's standard practice for a platform this comprehensive.
Here's a quick summary of my initial thoughts:
| What I Like | What Gives Me Pause |
|---|---|
| Comprehensive evaluation for prompts, RAG, & agents. | Pricing isn't public (likely enterprise-focused). |
| Excellent blend of automated and human feedback loops. | Might have a steep learning curve for non-technical users. |
| Supports a wide range of public and private models. | Being a newer platform, the community is still growing. |
| Customizable evaluators are a huge plus for niche tasks. |
Frequently Asked Questions about EvalsOne
- What is EvalsOne primarily used for?
- It's used for systematically evaluating and optimizing generative AI applications. This includes testing LLM prompts, analyzing the performance of Retrieval-Augmented Generation (RAG) systems, and validating the behavior of complex AI agents.
- Does EvalsOne support custom or private AI models?
- Yes, and this is a major strength. Besides integrating with popular models like GPT and Claude, it allows you to connect to your own locally-hosted or private fine-tuned models via APIs.
- Is EvalsOne suitable for beginners in AI?
- Probably not. The platform is designed for professional developers and teams with some technical expertise. Its concepts are rooted in software development and MLOps, so it assumes a certain level of knowledge.
- Can I incorporate human feedback into my evaluations?
- Absolutely. EvalsOne has a built-in feature for integrating manual, human-in-the-loop evaluation, allowing you to score outputs based on subjective qualities that automated tests might miss.
- How much does EvalsOne cost?
- The pricing is not publicly listed. You need to contact their team and book a demo to get a quote, which suggests a custom pricing model tailored for professional teams and enterprises.
- How is this different from a tool like the OpenAI Playground?
- A playground is for single, ad-hoc tests. EvalsOne is a structured, collaborative platform for running large-scale evaluations with multiple data samples, comparing results over time, and generating quantifiable metrics and reports. It's about process, not just experimentation.
My Final Verdict on EvalsOne
So, is EvalsOne the real deal? From what I can see, I'm genuinely optimistic. It's not just another shiny object; it’s a tool that addresses a fundamental, gaping hole in the current generative AI development stack. The Wild West needs a sheriff, and the world of alchemy needs the scientific method. EvalsOne appears to be a strong candidate for both roles.
It brings a much-needed layer of engineering discipline to prompt and model management. The focus on iterative improvement, comprehensive integration, and the mix of automated and human judgment shows a deep understanding of the actual problems developers face. While the lack of public pricing and its newness in the market are points to consider, the platform's capabilities are, on paper, exactly what serious AI teams should be looking for.
If you're part of a team that's moved beyond just playing with AI and is now trying to build reliable, high-quality products with it, then I’d say booking a demo with EvalsOne is probably a very, very good use of your time.