Another Monday, another groundbreaking LLM that’s supposed to change everything. Right? If you're in the AI space, you know the feeling. The churn is real. One week, Claude 3 is the king, the next, a new Llama variant drops, and then some dark horse model from a research lab you've never heard of is suddenly the talk of the town. Keeping up is a full-time job.
But the real problem, the one that keeps developers and product managers up at night, is this: how do you actually know which model is better? Not just on some generic benchmark, but for your specific application. For your customers. For your data. For years, the answer has been a messy combination of gut feelings, expensive human evaluation, and squinting at two responses side-by-side until your eyes glaze over. It’s slow, it’s biased, and honestly, it’s a massive pain.
I’ve been watching the MLOps space for a long time, and I've been waiting for a tool that seriously tackles this evaluation bottleneck. A few weeks ago, I stumbled upon AutoArena, and I gotta say, it’s one of the most promising solutions I’ve seen. It’s not just another leaderboard; it’s a whole system for making AIs fight it out so you can just crown the winner.
The Real Headache of Judging AI
Before we get into what AutoArena does, let’s get real about the problem. Manually evaluating generative AI is a special kind of torment. You write a prompt, get two slightly different answers from two different models, and then you have to decide which is “better.” What does better even mean? More creative? More accurate? More concise? Safer? Your definition might be different from your colleague's, and both your definitions are probably different from your user's.
Some folks tried to automate this using a single, powerful LLM—like GPT-4—as a judge. A decent first step, but it’s like asking a Ford engineer to be the sole judge of a Ford vs. Chevy competition. You’re going to get some inherent bias. You're just trading one set of problems for another. We needed something more robust, something that felt less like a coin flip and more like a scientific process.
So What Exactly is AutoArena?
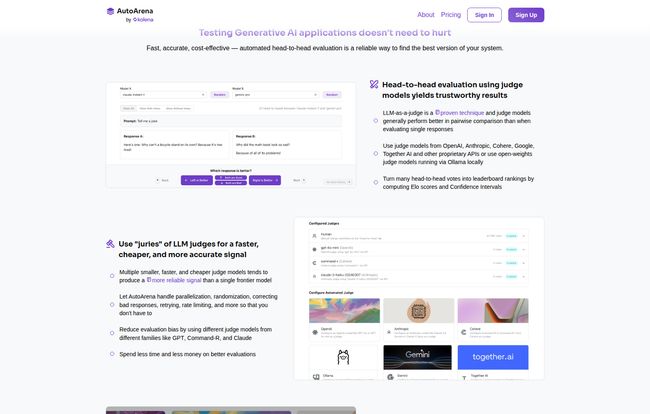
In a nutshell, AutoArena is an open-source tool that automates head-to-head battles between GenAI systems. Think of it as a gladiator arena for your models. You pit two contestants—be it two different LLMs like Gemini and Claude, two versions of your RAG pipeline, or even just two different system prompts—against each other. You give them a task, and then an automated “judge” decides the winner.
Visit AutoArena
But here’s the clever part. It’s not just one judge. AutoArena uses a whole jury of judges. This is the key. By getting opinions from a diverse set of judge models (OpenAI, Anthropic, Cohere, open-weights models, etc.), it averages out the individual biases and gives you a much more reliable signal. It’s the difference between asking one person for directions and asking a group of locals. You’re just more likely to get to where you’re going.
The Core Features That Got My Attention
I get pitched a lot of tools. Most are just slight variations of something else, but a few things about AutoArena really stood out to me as a long-time practitioner in this space.
Automated Juries for Fairer Fights
As I mentioned, the idea of using a “jury” of LLM judges is brilliant. The platform handles all the messy backend work—parallelization, randomization to avoid positional bias (you know, the tendency to prefer the response on the left), handling rate limits, and retrying failed API calls. This means you can spend less time writing boilerplate code and more time actually improving your product. It takes thousands of these head-to-head votes and crunches them into a leaderboard using Elo scores, just like in chess, so you can see a clear ranking of which models or prompts perform best.
Fine-Tuning Your Own AI Judge
This is the real power-user feature. Let's say you're building a legal AI assistant. A generic judge like GPT-4 might not appreciate the subtle nuances of legal citation. With AutoArena, you can collect a set of human preferences on your own data and use them to fine-tune a custom judge model. This judge is now aligned with your specific definition of quality. The team behind it claims their pre-tuned models on the professional plan can achieve >10% accuracy improvements over standard foundation models. For a business, that kind of edge is huge.
Seamless CI/CD Integration with GitHub
Okay, for the developers in the room, this is probably the most exciting part. AutoArena can integrate directly into your continuous integration pipeline via a GitHub bot. Imagine this workflow: a developer on your team tweaks a system prompt and opens a pull request. Automatically, AutoArena kicks in, runs a head-to-head evaluation of the new prompt against the old one, and posts the results as a comment.
This change resulted in a 7% performance degradation on accuracy-related tasks.That’s not a gut feeling; that’s actionable data. It stops bad changes from ever reaching production. It's a total game-changer for maintaining quality at scale.
Let's Talk About the Price Tag
Pricing is always the big question, right? AutoArena has a pretty straightforward model that I think serves the community well.
First off, there’s the Open-Source version. It's completely free. You can `pip install autoarena`, host it yourself, and get access to the core application. This is fantastic for students, individual researchers, and anyone who wants to kick the tires and see how it works. It's licensed under Apache-2.0, so it's very permissive.
Next is the Professional plan, which comes in at $60 per user per month. This is their cloud-hosted offering at `autoarena.app`. For that price, you get team collaboration features, a slick UI, and—this is the main draw—access to their expertly fine-tuned judge models that boast higher accuracy. It seems geared towards startups and professional teams that want to move fast without managing their own infrastructure. They offer a two-week free trial, which is plenty of time to see if it’s a good fit.
Finally, there's the Enterprise plan. This is your classic "Contact Us" model for large organizations. It gives you everything in the Professional plan but allows for private, on-premise deployment on your own cloud (AWS, GCP, Azure) or internal servers. You also get SSO, priority support, and a say in their product roadmap. Standard big-company stuff.
The Good, The Bad, and The Nitty-Gritty
No tool is perfect. After spending some time with it, here's my honest breakdown.
The good stuff is obvious. Being open-source at its core is a massive plus. It automates a tedious, complex, and critical process, saving teams countless hours. The use of judge juries to reduce bias is a thoughtful and effective approach. And I can't say it enough: the GitHub integration for CI/CD is just brilliant for any serious development team.
On the flip side, it's not exactly a plug-and-play tool for a non-technical person. You do need some technical expertise to get it set up and configured, especially the self-hosted version. That’s not really a flaw, just the nature of the beast. Also, while the core is free, the most powerful and convenient features—like the cloud hosting and their pre-tuned, high-accuracy judges—are behind the paid subscription. It's a fair business model, but its something to be aware of.
My Final Take: Is AutoArena Worth Your Time?
So, what’s the verdict? In my experience, the biggest bottleneck in applied AI isn't building the first version; it's iterating and knowing, with confidence, that you’re making it better. AutoArena directly attacks that problem.
If you're an indie developer, a researcher, or a small team just getting started, the open-source version is a no-brainer. It gives you a powerful evaluation framework for free. If you're part of a professional team where GenAI is core to your product, I’d seriously look at the Professional plan. The time saved on manual evaluation and infrastructure management could easily justify the cost within the first month.
AutoArena is a serious tool for a serious problem. It helps shift the process of LLM development from an art, guided by instinct, to a science, driven by data. And in a world filled with so much AI hype, that’s exactly what we need.
Frequently Asked Questions
- What is AutoArena in simple terms?
- AutoArena is an automated tool that helps you test and compare different AI models or prompts. It sets up head-to-head competitions and uses a panel of other AIs as "judges" to determine which one performs better, then ranks them on a leaderboard.
- Is AutoArena free to use?
- Yes, the core AutoArena application is open-source and free to use if you host it yourself. They also offer paid plans for cloud hosting, team collaboration, and access to more accurate, pre-tuned judge models.
- What are LLM judges?
- An LLM judge is a large language model (like GPT-4 or Claude 3) that is prompted to act as an impartial evaluator. It's given two different AI-generated responses to the same prompt and asked to decide which one is better based on a set of criteria.
- How is this better than just having people review the outputs?
- Human review is excellent for quality but is very slow, expensive, and can be inconsistent. AutoArena provides a way to run thousands of evaluations quickly and cheaply, providing a scalable way to get a strong directional signal on which model or prompt is performing better. It's best used to complement, not entirely replace, human oversight.
- Can I use my own private models with AutoArena?
- Yes. Since you can run the open-source version on your own infrastructure, you can point it to any model API, including private, fine-tuned models you host yourself. This allows you to evaluate proprietary models in a secure environment.
Conclusion
The race to build better and more helpful AI is on, but you can't win a race if you don't have a finish line. For too long, evaluating our creations has felt like guesswork. We've been flying blind, relying on anecdotal evidence and small-scale tests. Tools like AutoArena are turning the lights on. They provide a structured, data-driven, and scalable way to measure progress, catch regressions, and build better AI products with confidence. It’s a crucial piece of the MLOps puzzle, and one I’ll be keeping a very close eye on.